Machine Learning Inference with GitHub Actions
- 6 minsI just looked up the recently introduced GitHub Actions and my first thought was to create an quick example project where we “deploy” an ML model with this new feature. Of course this is not a “real deployment”, but it can be used to test your model inside the repository without any additional coding. Also you can look super cool when you say to your boss, - “just leave an issue comment at the repo I’ve created”. Moments later a new notification will appear for him/her with the model’s prediction.
You can find the complete GitHub repo here
GitHub Actions is an automation tool for building, testing and deployment. Quick example: every time you create a Pull Request (with a certain tag), a new build will be triggered for your application and then it can send a message to a senior developer to have a quick look on your code.
What will we create?
A custom action and an automatic workflow will be created on top of a repository with which you can use your trained model and is triggered when a new comment arrives under an issue. You can also find the model training and inference code. I wanted to be super hardcore, so I chose the Iris dataset and a Random Forest Classifier. This tree ensemble model is trained so it can identify flowers based on the sepal and petal lengths and widths.
Training of the model was done in a Jupyter Notebook here (I’ll leave the explanation out as there is nothing interesting about it and you can find dozens of tutorials online). The code trains and serializes the model which we will use for the predictions. The GitHub Actions workflow is triggered when an issue receives a comment. If the comment contains the /predict prefix, then we start to parse the comment, then we make a prediction and construct a reply. As the final step this message is sent back to the user by a bot under the same issue. To make things better, this whole custom action will run inside a Docker container.
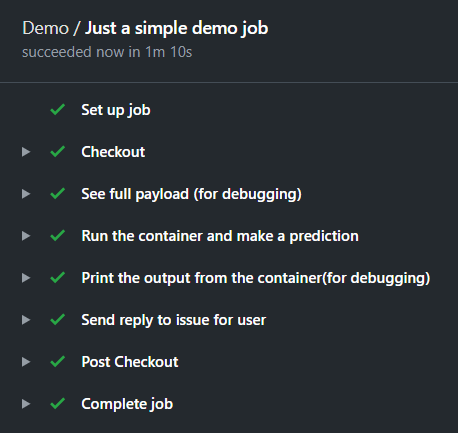
In a workflow we will find steps and for certain steps we can create individual actions. One workflow can contain multiple actions, but in this project we will use a single one.
Create an Action
As a first step we should create our action in the root folder named action.yaml. In this we can describe the inputs, outputs and the run environment.
From top to bottom you can see 3 defined inputs and a single output. At the end the runs key describes the environment where our code will run. This is a Docker container for which the inputs will be passed as arguments. Therefore the entry point of the container should accept these 3 arguments in the defined order.
The container
When we take a closer look at the Dockerfile we can see how our run environment is built up. First we install all the listed python requirements. Then the entrypoint.sh is copied and made executable, so it can be run inside the container. Lastly the serialized sklearn model file is copied to the container, so we can use it for making prediction (in a real life scenario, you should not store model files in a repo. This is just for the sake of quick demonstration and my laziness).
Define the Workflow
An action can not be used without a workflow. That defines the different steps you would like to take in your pipeline. You can find it at .github/workflows/main.yaml.
First of all on: [issue_comment] defines that I would like to trigger this flow when an issue receives a comment (from anyone at any issue). Then in my job I define the VM type with runs-on: ubuntu-latest (This is can be self-hosted or by GitHub). Now comes the interesting part, the steps which I mentioned before.
- Checkout step: with this step we move to the desired branch in our repository (this is a github action also).
- See the payload: I left it here for debugging. It shows the whole payload after receiving a comment under an issue. This container, the comment, the issue number, the user who left the comment, etc.
- Make the prediction: This is the one for our custom action. The
if: startsWith(github.event.comment.body, '/predict')line makes sure this step runs only if a valid prediction request comes in (so it contains the/predictprefix). You can see the inputs are defined under thewithkeyword and the values are added from the payload through their keys (likegithub.event.comment.body). - Print the reply: The constructed reply is echoed to the log. It uses the defined output of out previous step:
steps.make_prediction.outputs.issue_comment_reply. - Send reply: The created reply which contains the prediction is sent as a reply with the script
issue_comment.sh.
Every step runs on the selected runner which is the ubuntu-latest except our action which runs inside the created container. This container is built when the workflow is triggered. (I could have cached it, so a single run from the flow can use a previously built image, but again, I was lazy adding it to this example).
Making the prediction
There is one thing I’ve not talked about: how the prediction is made? You can easily figure this out by looking at the main.py script.
First of all the serialized sklearn model is loaded. Then the comment is parsed and we receive the 4 feature which can be used to identify the flower (sepal length, sepal width, petal length, petal width). With the 4 floats we use the model to make a prediction. The last step is to construct the reply message and then set it as an output which is done with the print(f"::set-output name=issue_comment_reply::{reply_message}") line.
That’s it! Okay… I know what you are thinking. This is too easy: The input, the dataset, the model, the storage of the mode, how the request is handled, etc. But I am suer you can figure out how to develop you method from here. (E.g. for image inputs you could decode from a base64 string and then run it through your Deep Learning model which is stored in GitLFS.)
Try it out
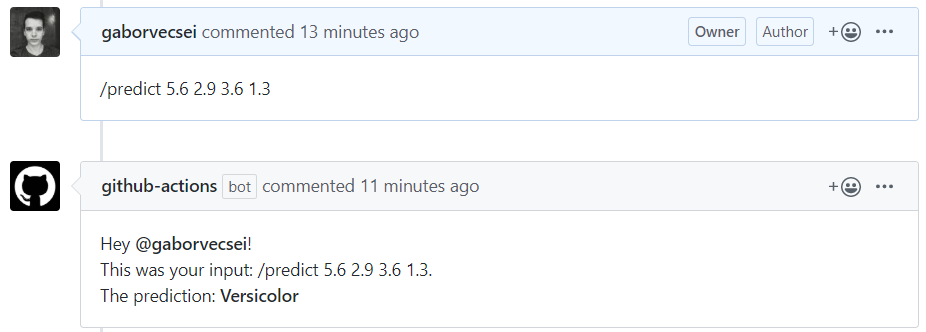
Now that you have read all this, and you are wondering what I’ve talked about, just go here and send a new comment like this:
/predict 5.6 2.9 3.6 1.3
You will receive the prediction in 1-2 minutes.

Gábor Vecsei
I love chocolate